python人気ですよね。
昨年、データサイエンティストの素養も身に付けがてら会社のデータの統計を取れると面白いかもと思って、python本買って触ってみたところ、お手軽さとか、記述の簡潔さとか、ライブラリーの充実さとかに感動しました。
サクッと書けるし、利便性も高い。これはいいぞと思って、もっとpython使ってみようと思うようになりました。
pythonといえば、AIとか統計とかWebスクレイピングで使う人が多い印象を受けるのですが、業務上、ブラウザを使って作業をすることが多いので、「いよいよSeleniumを使う時が来た!」と思って使ってみることにしました。
マーケティング上、キーワードに対する検索結果の傾向などを見るのは重要なので、最初は、Googleの検索結果ページから情報を取得しようかと考えたら、Googleは、プログラムなどでの取得は禁止しているそうなので泣く泣く諦めました。
そしたら以下の記事がありました。
Custom Search APIを使ってGoogle検索結果を取得する
https://qiita.com/zak_y/items/42ca0f1ea14f7046108c
これを見て、検索結果を返すAPIがあるのでそっちを使えば良さそうだなと。
細かい話は上記のリンクを見ていただくとして、まぁ、制限があったり、通常のGoogle検索に比べて検索結果の数が少なかったりってデメリットがあったりしますが、傾向を調べるなら十分なんじゃないでしょうか?
Google検索とCustom Search APIで、どうにか同じ検索結果にしてやろうとやっきになったことがありますが、Googleのフォーラムかなんかで、そもそも両者はエンジン自体が違うから同じ結果にはならないみたいなことが書いてありました。そういわれると、納得し、同じ結果を求めることは諦めました。
さて、先ほどの記事のプログラムを少し応用します。やりたいことは、ある対象キーワードの検索結果上位10サイトの中を順番に見て、そのサイト内に対象キーワードをタイトルに含むページは何ページくらいあるかを探ってみます。
from time import sleep
import sqlite3
import re
from googleapiclient.discovery import build
GOOGLE_API_KEY = "******"
CUSTOM_SEARCH_ENGINE_ID = "******"
def getSearchResponse(keyword):
service = build("customsearch", "v1", developerKey=GOOGLE_API_KEY)
# とりあえず1ページ目だけ検索結果を取得する
page_limit = 1
start_index = 1
response = []
for n_page in range(0, page_limit):
try:
sleep(1)
response.append(service.cse().list(
q=keyword,
cx=CUSTOM_SEARCH_ENGINE_ID,
lr='lang_ja',
num=10,
start=start_index
).execute())
start_index = response[n_page].get("queries").get("nextPage")[0].get("startIndex")
except Exception as e:
print(e)
break
# データベースを開く
connect = sqlite3.connect("keywords.db")
cursor = connect.cursor()
# TABLEが無い時に作成
cursor.executescript("CREATE TABLE IF NOT EXISTS search_words(id integer primary key, keyword, totalResults)")
cursor.executescript("CREATE TABLE IF NOT EXISTS search_results(id integer primary key, keyword_id, title, link, snippet, totalResults)")
cnt = 0
sqlWordId = 0
sqlResultId = 0
colums = 0
for one_res in range(len(response)):
totalResults = response[one_res]['searchInformation']['totalResults']
cursor.execute("INSERT INTO search_words (keyword, totalResults) VALUES (?,?)", (keyword, totalResults))
# このキーワードのsearch_wordsテーブル上のidを取得する
cursor.execute("SELECT id FROM search_words WHERE keyword=?",(keyword,))
colums = cursor.fetchall()
sqlResultId = colums[len(colums)-1][0]
print(sqlResultId)
if 'items' in response[one_res] and len(response[one_res]['items']) > 0:
# 検索結果を順に見ていく
for i in range(len(response[one_res]['items'])):
cnt += 1
display_link = response[one_res]['items'][i]['displayLink']
title = response[one_res]['items'][i]['title']
link = response[one_res]['items'][i]['link']
snippet = response[one_res]['items'][i]['snippet'].replace('\n', '')
response2 = []
# ドメインを取得します
domain = re.sub("^((http|https)://[^/]*).*", "\\1", link)
# ドメイン内で、intitle:検索をして、タイトルをキーワードに含む検索結果を取得
try:
sleep(1)
response2.append(service.cse().list(
q="intitle:"+keyword,
cx=CUSTOM_SEARCH_ENGINE_ID,
lr='lang_ja',
num=1,
start=1,
siteSearch=domain
).execute())
except Exception as e:
print(e)
break
cnt2 = 0
# intitle:検索結果からタイトルにキーワードが含まれるページ数を取得
for one_res2 in range(len(response2)):
if 'items' in response2[one_res2] and len(response2[one_res2]['items']) > 0:
for i in range(len(response2[one_res2]['items'])):
cnt2 += 1
title2 = response2[one_res2]['items'][i]['title']
link2 = response2[one_res2]['items'][i]['link']
snippet2 = response2[one_res2]['items'][i]['snippet'].replace('\n', '')
totalResults = response2[one_res2]['searchInformation']['totalResults']
# そのキーワードをタイトルに持つページ数をテーブルに挿入
cursor.execute("INSERT INTO search_results (keyword_id, title, link, snippet, totalResults) VALUES (?,?,?,?,?)", (sqlResultId, title2, link2, snippet2, totalResults))
# 保存を実行(忘れると保存されないので注意)
connect.commit()
# 接続を閉じる
connect.close()
if __name__ == '__main__':
target_keyword = 'python'
print("Searching following word:" + target_keyword)
getSearchResponse(target_keyword)sqlite3っていうデータベース言語を使っていますが、DB化しておくと、後で見る時に楽なのでよいです。sqlite3は、軽量で、お手軽なのがいいですね。
なお、「DB Browser for SQLite」ってソフトでデータベースを簡単に閲覧できます。このソフトで、先ほどのプログラムで作成される「keywords.db」を開くだけ。お手軽すぎて感動しました。
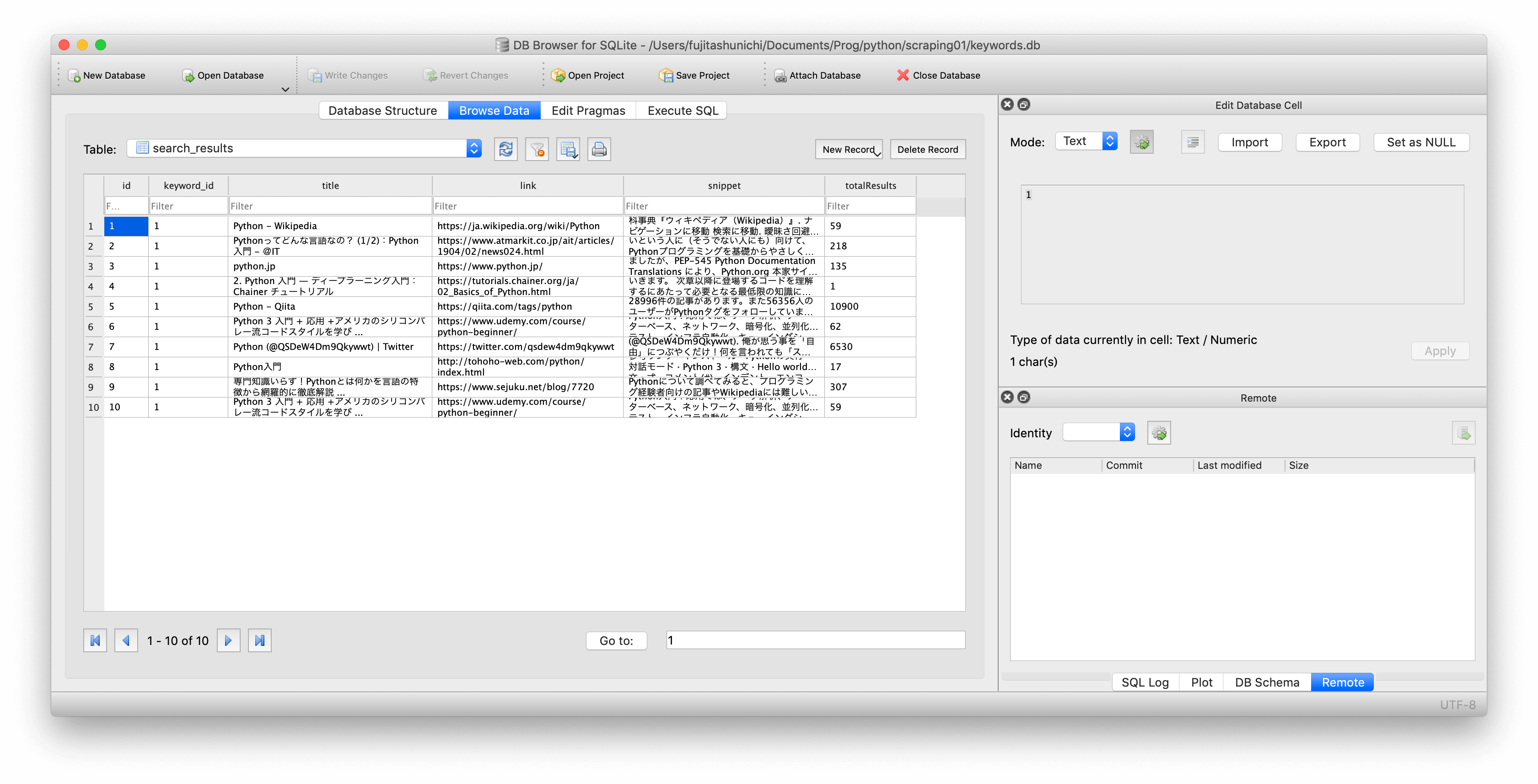
こうやって、キーワードをタイトルに含むページ数を出すと、競合がどれくらいそのキーワードに力を入れているのか参考になったりします。このようなプログラムで気になるキーワードを色々調べてみると面白いかもしれません。