以前以下のような記事を書きました。
PythonとSeleniumでインスタグラムの投稿にいいねをしてくれた人にいいねを返すプログラム
これを書いたのは2020年2月。もちろんこれはもう動かないのですよね・・・。
ちょっと久しぶりに動かしてみようと思いプログラムを修正しました。
今回の環境は以下の通り。
- MacBook Air(M1, 2020)
- OS:macOS Monterey(バージョン 12.1)
- Python:バージョン3.8.9
- Chrome:バージョン98.0.4758.80
前回と同じく、Pythonのwebdriverやtime、sys、re、randoを使いますので、pipなどを使ってインストールしておきましょう。
これまた同じく、selenium webdriverをダウンロードしておきます。自分の使っているChromeのバージョンに合わせましょう。今回の例では、98ですね。
selenium webdriverのchromeは以下からダウンロードできます。
ChromeDriver – WebDriver for Chrome
コードは大きく変わっている所はないのですが、Chromeのプロファイル情報使い方を変えました。
今までは、自分が普段使っているプロファイルを使っていました。ただ、今回の修正の際に、selenium webdriverのChromeを起動する度に、ログイン状態がリセットされてしまうという・・・。さらに、普段使いのChromeもログイン状態がリセット・・・。もともとログインが要らないようにプロファイルを使用する仕組みにしていたのに、毎回ログインが必要となると本末転倒です。
どうすればいいかと考えていた所、selenium webdriverのChrome用の新しいユーザーを作れば良さそうとなり、新規ユーザーを作りました。
コードの全体
コードの全体象はこちら
※2022年2月16日の時点では動作しました。
# coding: UTF-8
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
import sys
import re
import random
# 既存のChromeプロファイルを使う準備をします。
# 今回はselenium webdriverのchrome用のプロファイルを作成してそちらで一回instagramにログインしておきます。
options = webdriver.ChromeOptions()
options.add_argument('--user-data-dir=/Users/USERNAME/Library/Application Support/Google/Chrome/Profile 2')
# chromedriverのパスと、オプションを指定してドライバーを作成。
# あらかじめ使っているChromeのバージョンに合わせたchromedriverをダウンロードして/usr/local/bin/にいれておきます。
# executable_pathはdeprecatedとなったので、Serviceを使います。
browser = webdriver.Chrome(service=Service('/usr/local/bin/chromedriver'), options=options)
# 入力受付用の変数
inputURL = ''
# 最初に表示するページ(とりあえず適当に自分の投稿の一つを設定しておきます)
startURL = 'https://www.instagram.com/p/(投稿のID)/'
browser.get(startURL)
# --------------
# いいねしてくれた人の表示するボタンのパス
# --------------
likeListButtonPath = '//*[@id="react-root"]/section/main/div/div[1]/article/div/div[2]/div/div[2]/section[2]/div/div[2]/div/a'
# --------------
# いいねしてくれた人のリストの親コンテナーのパス
# --------------
likeListPath = '/html/body/div[6]/div/div/div[2]/div/div'
# --------------
# いいねしてくれた人のリストのパス
# --------------
likeListItemPath = '/html/body/div[6]/div/div/div[2]/div/div/div'
# --------------
# ユーザーの投稿一覧のパス
# --------------
postsPath = '//*[@id="react-root"]//article/div[1]/div/div[1]//a'
# --------------
# いいねボタンアイコン(SVG)のパス
# --------------
# 前回はいいね前もいいね後も同じアイコンのパスだったのが、別々になりました。そのため2つ用意
likeSvgPath = '//*[@id="react-root"]/section/main/div/div[1]/article/div/div[2]/div/div[2]/section[1]/span[1]/button/div[1]/*[name()="svg"]'
likeSvgPath2 = '//*[@id="react-root"]/section/main/div/div[1]/article/div/div[2]/div/div[2]/section[1]/span[1]/button/div/span/*[name()="svg"]'
# 投稿を格納する配列
posts = []
if __name__ == '__main__':
#===========================
# 起動
#===========================
browser.get(startURL)
time.sleep(random.randint(3, 8))
while True :
# インスタグラムの投稿URLの入力を受付
# exitが入力されたらプログラムを終了
print('INPUT YOUR POST URL')
print('(exit to command "exit")')
print('>>', end='')
stdin = input()
if stdin == 'exit' :
# connect.close()
browser.close()
sys.exit()
elif re.match(r'https:\/\/www\.instagram\.com\/p\/[ -~]{11}\/', stdin) :
print('URL CHECK OK : ' + stdin)
inputURL = stdin
browser.get(inputURL)
time.sleep(random.randint(3, 5))
else :
print('URL CHECK NG : ' + stdin)
continue
#==============================================
# 投稿にいいねした人のリストを取得
#==============================================
liker = []
# バージョンアップで、find_element_by_Xpathのような形式の関数は廃止になりまりました。代わりに以下の関数になります。Byクラスを使ってエレメントの取得方法を指定します。
likeListButton = browser.find_element(By.XPATH, likeListButtonPath)
likeListButton.click()
time.sleep(random.randint(4, 8))
likeList = browser.find_element(By.XPATH,likeListPath)
last_height = browser.execute_script("return arguments[0].scrollHeight", likeList)
time.sleep(random.randint(1, 3))
# 最後に到達するまでスクロールする
while True:
likeLists = browser.find_elements(By.XPATH,likeListItemPath)
for user in likeLists :
username = user.find_elements(By.TAG_NAME,'a')
liker.append(username[0].get_attribute('href'))
# スクロールは、JavaScriptで実行
browser.execute_script("arguments[0].scrollIntoView(false)", likeList)
time.sleep(random.randint(2, 5))
new_height = browser.execute_script("return arguments[0].scrollHeight", likeList)
if new_height == last_height:
break
last_height = new_height
# 重複を削除
liker2 = list(dict.fromkeys(liker))
print( 'いいねの数:' + str(len(liker2)) )
# ユーザー毎のループ
i = 0
for i in range(0, len(liker2)):
browser.get(liker2[i])
time.sleep(random.randint(5, 12))
print( "\nPERSON:" + str(i) )
print( browser.current_url)
posts = browser.find_elements(By.XPATH, postsPath)
post_urls = []
for post in posts:
post_urls.append(post.get_attribute('href'))
# 投稿毎のループ
i = 0
plen = 0
if len(post_urls) > 0:
plen = random.randint(1, len(post_urls))
else :
plen = len(post_urls)
for i in range(0, plen):
print( " 投稿インデックス:" + str(i))
print( " 投稿URL:" + post_urls[i] )
# 投稿ページへ
browser.get(post_urls[i])
time.sleep(random.randint(8, 20))
likeIcon = browser.find_elements(By.XPATH, likeSvgPath)
likeIcon2 = browser.find_elements(By.XPATH, likeSvgPath2)
if len(likeIcon) > 0 :
likeState = likeIcon[0].get_attribute('aria-label')
if likeState == 'いいね!':
print(' まだ「いいね」してないので「いいね」します')
favbtn = likeIcon[0].find_element(By.XPATH, './../..')
favbtn.click()
continue
else:
print(' 不明です')
elif len(likeIcon2) > 0 :
likeState = likeIcon2[0].get_attribute('aria-label')
if likeState == '「いいね!」を取り消す':
print(' この投稿はすでに「いいね」済み')
continue
else:
print(' 不明です')
else:
print(' いいねボタンが見つかりませんでした')
browser.close()
sys.exit()
コードの流れは前回と同じです。
- Selemiumでインスタグラムにアクセス。
- 標準入力で、投稿のURLを入力します。
- Selemiumが、入力された投稿のURLに飛び、いいねしてくれた人のリストを取得します。
- いいねしてくれた人を見にいきます
- その人の投稿を最新から順に(1〜3つ)見ていきます。
- いいねされていない投稿があれば、いいねします。
- 次の人の5へ。
-
リストを回りきったら、標準入力で投稿URLの入力を待ちます。(プログラムを終了するときは、ここで”exit”を入力)
※標準入力に投稿のURLを入力するときは手動になります
(復習がてら)コードの細かい解説
SVGの取得について
likeSvgPath = '//*[@id="react-root"]/section/main/div/div[1]/article/div/div[2]/div/div[2]/section[1]/span[1]/button/div[1]/*[name()="svg"]'
ここの部分ですが、
SVGは、
find_element_by_xpath('//*[@id="react-root"]/section/main/div/div[1]/article/div/div[2]/div/div[2]/section[1]/span[1]/button/div[1]/svg')のような書き方で取得できません。ということでしたね。
*[name()="svg"]というようにname()を使うことでsvg要素の取得ができます。
ログインについて
最初に説明しましたが、この部分は前回と変わりました。
ログイン済みのプロファイルを使うことでログインが不要になります。毎回ログインしない利点は、ログインする度にくるメール通知がこなくなるということですね。
# 既存のChromeプロファイルを使う準備をします。
# 今回はselenium webdriverのchrome用のプロファイルを作成してそちらで一回instagramにログインしておきます。
options = webdriver.ChromeOptions()
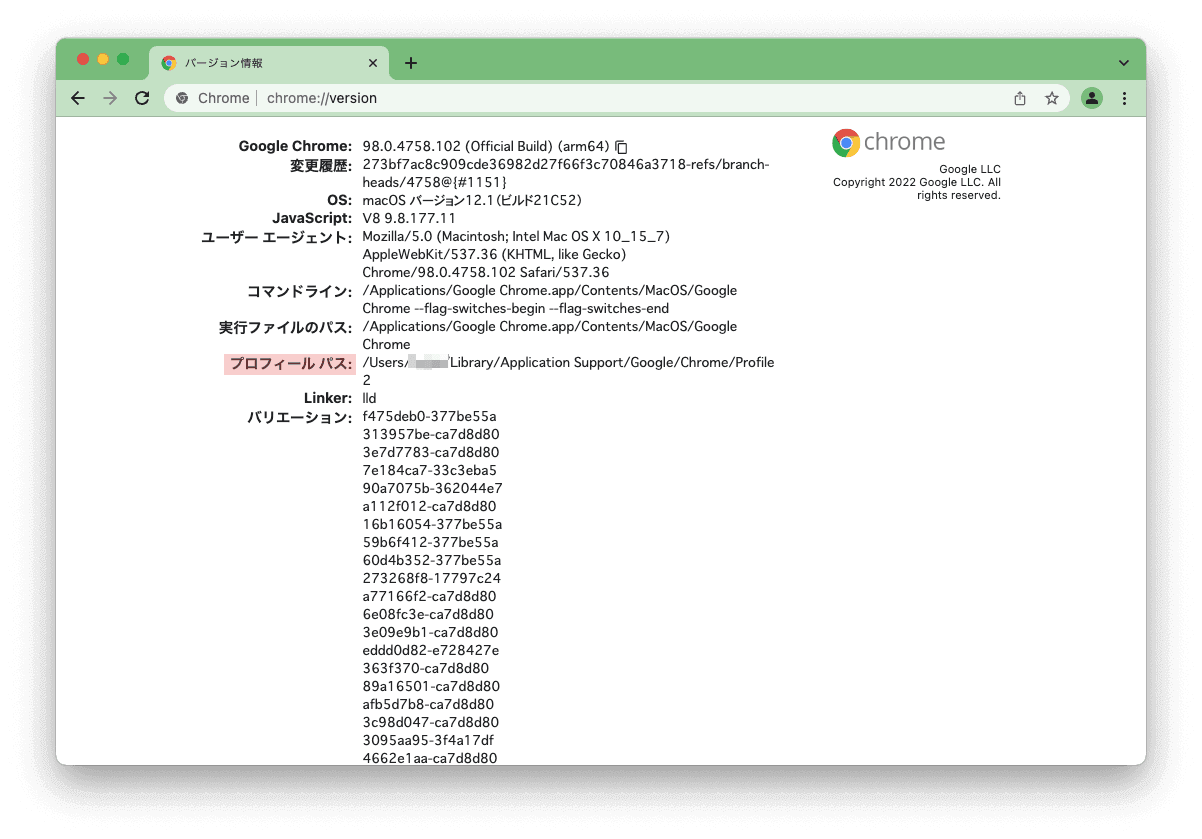
options.add_argument('--user-data-dir=/Users/USERNAME/Library/Application Support/Google/Chrome/Profile 2')まずは、プロファイルを作るところから。以下が分かりやすいです。
作成したプロファイルでChromeを開きURL欄にchrome://version/でプロファイルのパスを取得して、–user-data-dirに設定しましょう。
また、本バージョンでは、executable_pathによる指定は非推奨となり、エラーになるので、Seviceを使った指定にします。
# chromedriverのパスと、オプションを指定してドライバーを作成。
# あらかじめ使っているChromeのバージョンに合わせたchromedriverをダウンロードして/usr/local/bin/にいれておきます。
# executable_pathはdeprecatedとなったので、Serviceを使います。
browser = webdriver.Chrome(service=Service('/usr/local/bin/chromedriver'), options=options)
「USERNAME」の部分には、自分のユーザー名を入れてください。
参考
Python + Selenium + Chrome で自動ログインいくつか
標準入力で投稿のURLを入力
# インスタグラムの投稿URLの入力を受付
# exitが入力されたらプログラムを終了
print('INPUT YOUR POST URL')
print('(exit to command "exit")')
print('>>', end='')
stdin = input()
if stdin == 'exit' :
connect.close()
browser.close()
sys.exti()
elif re.match(r'https:\/\/www\.instagram\.com\/p\/[ -~]{11}\/', stdin) :
print('URL CHECK OK : ' + stdin)
inputURL = stdin
browser.get(inputURL)
time.sleep(random.randint(3, 5))
else :
print('URL CHECK NG : ' + stdin)
continue
この部分は、ターミナルからインスタグラムの投稿のURLを入力を受け付けて、そのURLがインスタグラムのURLとして正しいかチェック、問題なければ、次のフェーズにすすむ処理になっています。
標準入力は、input()で取得できます。
‘exit’が入力された場合は、プログラムを終了します。
このプログラムでは、たまに
time.sleep(random.randint(x,x))のような記述がありますが、あまりに早く処理しすぎると、インスタグラムの制限がかかり、アカウントが制限されたりします。そのために、少し処理を遅くするために、プログラムを停止しています。制限になるのには、さまざまな条件があるようなので気になる方は、調べて見てください。
いいねリストの取得
# 最後に到達するまでスクロールする
while True:
likeLists = browser.find_elements(By.XPATH,likeListItemPath)
for user in likeLists :
username = user.find_elements(By.TAG_NAME,'a')
liker.append(username[0].get_attribute('href'))
# スクロールは、JavaScriptで実行
browser.execute_script("arguments[0].scrollIntoView(false)", likeList)
time.sleep(random.randint(2, 5))
new_height = browser.execute_script("return arguments[0].scrollHeight", likeList)
if new_height == last_height:
break
last_height = new_height
以前の書き方
find_elements_by_xpath(・・・)このような要素取得系の関数は、バージョンアップの関係で非推奨になりました。Javaなどのseleniumと同じように、pythonもByクラスを使って何をもとに指定するようになりました。
Byを使った書き方
find_elements(By.XPATH,・・・)参考
find_element_by_* commands are deprecated in selenium
さて、いよいよ本題ですが、いいねしてくれた人リストは、1回で取得しようとしてもできません。
Reac製のサイトなどをみると大体がそうなので、Reacの仕様だと思うのですが、スクロール要素内のリストなどは、表示分+αがDOMとして動的に生成されていて、表示分から遠い位置にある要素は、そもそもDOMとして存在しないようになっています。表示されない要素をDOMとして置いておいても無駄ってことですね。
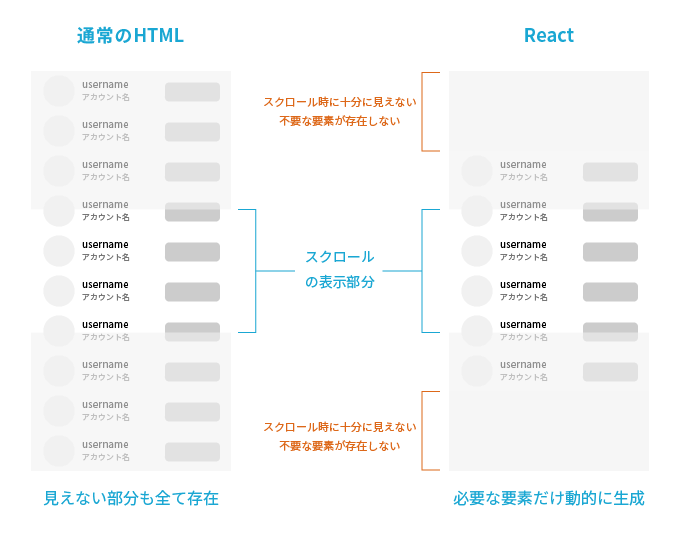
ですので、少しスクロールして、そこでDOMとして存在する人を取得、そしたらまたスクロールして、取得・・・を繰り返していきます。
スクロールは、Pythonだけではできないので、execute_script()を使い、JavaScriptでスクロールするようにします。
scrollIntoView(false)で、見えている部分の下端までスクロールしてくれます。
スクロールしたら、scrollHeightで現在のいいねしてくれた人の部分のスクロール位置を取得します。
スクロールが最下端にいったら、スクロール位置は大きくならないので、そこで、ループを抜ける仕組みです。
詳しくは、以下を見てください。
参考1
あまり知られてなさそうなメソッド element.scrollIntoView()
参考2
How can I scroll a web page using selenium webdriver in python?
ここで、取得したリストには、表示部分より少し多めにユーザーが表示されています。
例えば、見える人が真ん中の3人で、スクロールエリア外の見えないエリアの上下に1人ずつ存在する場合は、
1回目:A、B、C、D、E (B、C、Dが見える)
2回目:B、C、D、E、F (C、D、Eが見える)
3回目:C、D、E、F、G (D、E、Fが見える)
という風に取得することになります。
Bは2回、Cは3回、Dも3回・・・というように重複してしいまいます。
そのため重複してリストに入っているいるユーザーがいるので、
liker2 = list(dict.fromkeys(liker))
で、重複を削除します。
参考
Pythonでリスト(配列)から重複した要素を削除・抽出
いいねくれた人達の投稿をみていき、いいねする
プログラムも終盤、実際にいいね!を返します。
likeIcon = browser.find_elements(By.XPATH, likeSvgPath)
likeIcon2 = browser.find_elements(By.XPATH, likeSvgPath2)
if len(likeIcon) > 0 :
likeState = likeIcon[0].get_attribute('aria-label')
if likeState == 'いいね!':
print(' まだ「いいね」してないので「いいね」します')
favbtn = likeIcon[0].find_element(By.XPATH, './../..')
favbtn.click()
continue
else:
print(' 不明です')
elif len(likeIcon2) > 0 :
likeState = likeIcon2[0].get_attribute('aria-label')
if likeState == '「いいね!」を取り消す':
print(' この投稿はすでに「いいね」済み')
continue
else:
print(' 不明です')
else:
print(' いいねボタンが見つかりませんでした')
今回、この部分も変わりました。
以前は、いいね!アイコンと、いいね済みアイコンは同じ要素で状態が変わっていたのですが、今回、いいね!アイコンといいね済みアイコンが別物になっています。ですので、いいねしたかしてないかは、アイコンがそれぞれ存在するかで見ます。
いいねしてくれた人を順番に回り、全て回り終わったら、投稿URLの入力フェーズに戻ります。
他の投稿のいいねくれた人にも返したい場合は、続けて別の投稿のURLを入力すれば、またいいねを返します。
ただ、いいね返しが、結構時間かかるので、のんびり待ちましょう。
前回も言ったようにtime.sleepの値を短くすれば早いのですが、あまり早くすると制限されてしまので気をつけましょう。